





Wer erklärt dem KI-Agenten, was das Unternehmen weiß?
Der blinde Fleck im KI-Hype
Stellen wir uns folgende Situation vor: Ein Team von kollaborierenden KI-Agenten einer Bank soll Kunden identifizieren, die von Naturkatastrophen betroffen sind, und ihnen proaktiv finanzielle Unterstützung anbieten, inklusive konsistenter, richtlinienkonformer Entscheidung über Kreditverzicht. Der Agent muss dafür Kunden-, Kredit-, Risiko- und Immobiliendaten zusammenführen, Nachrichtendaten und Wetterdaten integrieren, und dabei Datenschutzregeln, Unternehmensrichtlinien und regulatorische Anforderungen einhalten.
In diesem Szenario treffen die KI-Agenten zahlreiche Entscheidungen mit und über Unternehmensdaten. Schnell, konsistent, skalierbar. Aber auf welcher Grundlage? Wessen Verständnis von „Kunde“, wessen Definition von „Risiko“ verwenden sie? Welche Compliance-Anforderung gilt hier: die globale Richtlinie oder die regionale Ausnahme?
Die meisten Diskussionen über Agentic AI beginnen mit planenden, orchestrierenden, eigenständig handelnden Systemen. Fähigkeiten, die beeindrucken. Aber die eigentlich relevante Frage lautet: Wer gibt dem Agenten das Unternehmenswissen, den Business-Kontext mit? Genau hier liegt der blinde Fleck in Führungsetagen ebenso wie in IT-Architekturen.
Das Wissen, das in keinem System steht
Organisationswissen lebt in Köpfen, in eingespielten Prozessen, in informellen Absprachen. Menschen kennen die Leitplanken für ihr Handeln und entwickeln so Vertrauen in Entscheidungen. Erfahrene Kolleginnen und Kollegen wissen, dass „Kunde" im Vertrieb etwas anderes bedeutet als im Risikomanagement. Sie kennen die Ausnahmen, die Grauzonen, die ungeschriebenen Regeln.
Sobald jedoch Maschinen mitentscheiden oder gar eigenständig handeln, wird dieses implizite Wissen zum strukturellen Risiko. KI-Agenten kennen keine Grauzonen, die ihnen niemand erklärt hat. Sie arbeiten mit dem, was explizit definiert und referenzierbar ist. Was nicht definiert ist, existiert für sie nicht.
Was wir oft sehen: Agenten und KI-Anwendungen, die im Labor brillieren, von denen sich aber niemand traut, sie in Produktion zu nehmen. Nicht weil die Technologie versagt, sondern weil der Kontext und damit das Vertrauen fehlt.
Der Hebel: Kontext als gemeinsame Sprache
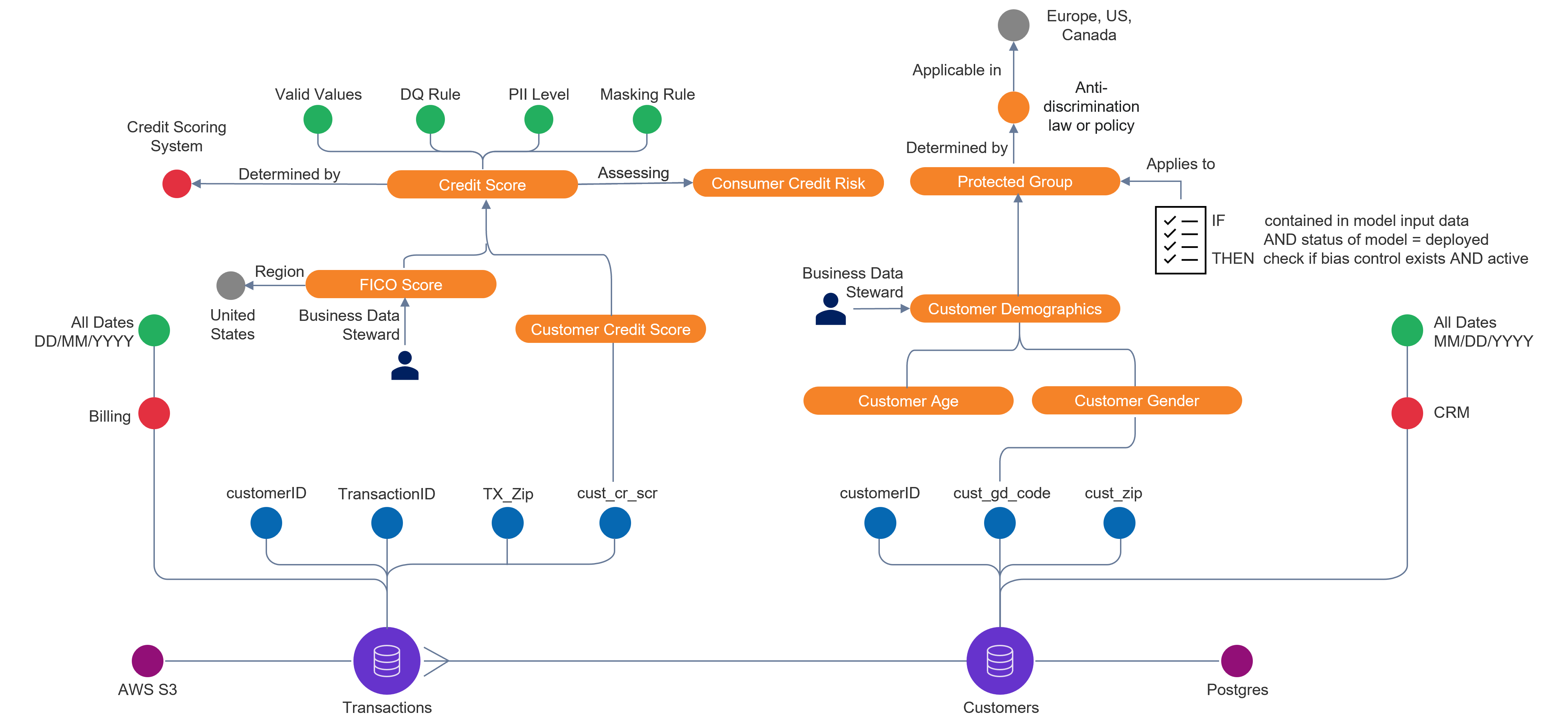
Die Antwort darauf ist kein weiteres KI-Modell und hat auch nur mittelbar mit Technologie zu tun. Es ist ein konzeptueller Schritt, den viele Unternehmen noch vor sich haben: Business-Kontext muss als referenzierbare Größe externalisiert werden, die für Menschen und Maschinen gleichermaßen gilt. Aus meiner Sicht ist ein Data Knowledge Graph hier ein fundamentaler Schritt. Er macht explizit, was ein Unternehmen weiß: Welche Bedeutung und Beziehungen haben unsere zentralen Geschäftsbegriffe? Welche Regeln gelten wo? Welche Daten bedeuten wo was und sind vertrauenswürdig. Zu welchem Zweck darf ich sie verwenden und warum sind sie geeignet?
Dieser gemeinsame Bedeutungsraum ist Referenz und gleichzeitig Lingua Franca zwischen Mensch und Maschine. Er gibt KI-Agenten den Kontext, den sie brauchen, um verlässlich zu handeln. Er gibt Menschen die Transparenz, die sie brauchen, um Entscheidungen nachzuvollziehen und zu vertrauen.
Siehe: Data Knowledge Graph
Skalierung als Vertrauensfrage
Solche Graphen, geschickt und teilautomatisch aufgebaut, sind mehr als ein technisches Konstrukt. Sie schaffen Vertrauen zwischen Mensch und Maschine. Governance wird damit kein nachträglicher Kontrollmechanismus mehr, sondern ein aktives Steuerungselement: eingebettet in die Daten, durchgesetzt in der Ausführung, nachvollziehbar für Auditoren und Regulatoren. Vertrauen wird eine belegbare Eigenschaft des Systems.
Hier liegt der eigentliche strategische Hebel: Wer Business-Kontext einmal sauber externalisiert hat, kann skalieren. Fachanwender bekommen Zugriff auf die richtigen Daten im richtigen Kontext. Agenten bekommen das Wissen, das sie brauchen, um verlässlich zu handeln. Und Richtlinien werden nicht dokumentiert, sondern automatisch durchgesetzt
Die organisatorische Dimension
Das setzt allerdings voraus, dass Unternehmen bereit sind, Verantwortung für Daten neu zu verteilen. Und das ist die eigentliche organisatorische Herausforderung. Nicht die Technologie blockiert, sondern eingespielte Zusammenarbeitsmodelle, in denen das Business Anforderungen stellt und die IT liefert. Ein Data Knowledge Graph hilft, dieses Modell zu verschieben: Business-Einheiten werden zu Eigentümern von Bedeutung. Sie definieren Begriffe, Regeln und Kontexte, für die sie auch die Verantwortung tragen. Das erfordert neue Rollen, neue Prozesse und eine Bereitschaft zum Experimentieren, die in vielen Organisationen erst am Anfang steht.
Was Agenten können, wenn sie wissen, was sie tun
Kehren wir zum Ausgangsszenario zurück. Das Agenten-Team der Bank hat jetzt Zugriff auf einen gemeinsamen Bedeutungsraum: Es weiß, welche Kunden betroffen sind, welche Richtlinien gelten, welche Ausnahmen zulässig sind und warum. Es handelt schnell, weil der Kontext nicht erst zur Laufzeit zusammengesucht werden muss. Es handelt konsistent, weil Regeln nicht interpretiert, sondern referenziert werden.
Für Mitarbeiter bedeutet das: Sie müssen dem Agenten nicht blind vertrauen. Sie können nachvollziehen, auf welcher Grundlage er entschieden hat. Das ist der Unterschied zwischen einem System, das Angst macht, und einem, das Entlastung schafft. Der Business Impact im Beispiel ist greifbar: schnellere Hilfe in der Krise, geringeres Portfoliorisiko, stärkere Kundenbindung und jede Entscheidung revisionssicher dokumentiert.
Technologie kann helfen, diesen Kontext zu operationalisieren. Aber die Entscheidung, ihn zu schaffen, ist eine menschliche – und eine strategische.
.png)
.svg)





.jpg)